

Table of Contents
The SnackHack2 source code can be found on my GitHub with the link. More information about this tool, can be found at my other article with the name SnackHack2: Hacking tool and Recon.
Port Scanning IPs
require './lib/snackHack2'
for i in 0..255
puts "167.71.98.#{i}"
tcp = Snackhack2::PortScan.new
tcp.ip = "167.71.98.#{i}"
tcp.run
i += 1
print("\n\n")
end
tcp.delete = true
tcp.ports_extractor("22")
This script will perform a port scan of the first 1,000 ports. The code will create a new file, with a name like “127.0.0.1_port_scan”.
Since “delete” is set to true, after extracting all the scans with port “22” open. The code will delete the files and save all the IPs with port 22 open in one file.
Getting Information About a Site
The ruby gem “colorize” must be installed for this script. Snackhack2 also needs to be installed.
The code will perform a bunch of different tests on the site to figure out what CMS the site is using, the webserver version, it will check to see if the site is using Google Analytics, as well as perform banner grabbing and checking the site’s Robots.txt file for open or sensitive directories. The code will also list the site’s meta data tag.
require 'snackhack2'
require 'colorize'
print("Enter URL (with HTTPS://): ")
url = gets.chomp
print("\n\n\n")
puts "[+] Checking for Drupal...\n".red
Snackhack2::Drupal.new(url).all
puts "--------\n"
puts "[+] Checking for WordPress...\n".red
Snackhack2::WordPress.new(url).run
puts "--------\n"
puts "[+] Checking for TomCat...\n".red
Snackhack2::TomCat.new(url)
puts "--------\n"
puts "[+] Checking the site for Google Analytics...\n".red
Snackhack2::GoogleAnalytics.new(url).run
puts "--------\n"
puts "[+] Grabbing the Banner...\n".red
Snackhack2::BannerGrabber.new(url).run
puts "--------\n"
puts "[+] Checking Robots.txt...\n".red
Snackhack2::Robots.new(url).run
puts "--------\n"
puts "[+] Checking Website Meta...\n".red
Snackhack2::WebsiteMeta.new('https://x.com').run
puts "--------\n"
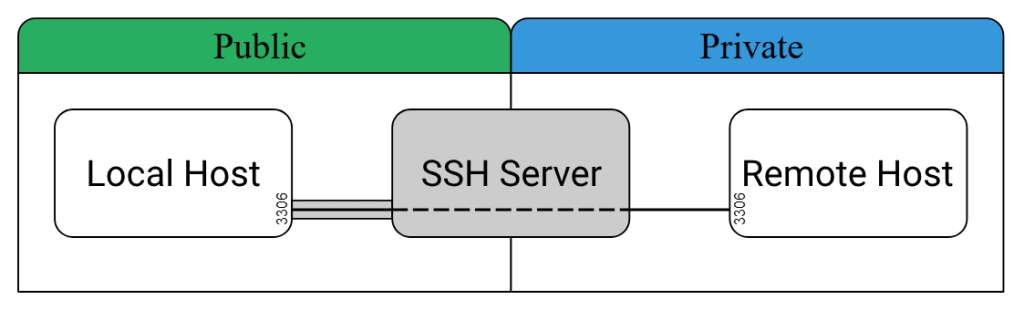
Remote SSH Forwarding
More information about SSH Forwarding can be found here. There are a couple other types of SSH such as forward SSH and local SSH. I would definitely check out the site listed above.
There are some pretty cool stuff that can be done with SSH tunneling. Like for example you could run a local website on one server or VPS and then create a SSH tunnel where you can tunnel your traffic so that you can access the locally hosted server.
You could use a SSH tunnel for a box to connect back to your machine, creating a reverse shell that you can remotely connect and run commands on a remote box.
require './lib/snackHack2'
ssh = Snackhack2::SSHForwardRemote.new
ssh.site = "187.171.198.132"
ssh.user = "root"
ssh.pass = "secretpassword"
ssh.key = "/home/JakeFromStateFarm/.ssh/id_rsa"
ssh.lport = 2222
ssh.lsite = "localhost"
ssh.rport = 8022
ssh.run
LocalScan
This script will find all the hosts on a network and print out their IPs. The script will perform a ‘list’ scan and if nothing is found it will run a ‘ping’ scan and print out the IPs found,
require_relative '../lib/snackHack2'
require 'colorize'
def ping_scan
sl = Snackhack2::ScanLocal.new
sl.ip_range = "192.168.1.0/24"
file = sl.ping_scan
sl.read_file = file
up = sl.get_up_hosts_from_file
unless up.empty?
puts "IPs FOUND: ".green
up.each do |ip|
puts ip
end
end
end
def list_scan
sl = Snackhack2::ScanLocal.new
sl.ip_range = "192.168.1.0/24"
file = sl.list_scan
sl.read_file = file
up = sl.get_up_hosts_from_file
# Makes sure that there were IPs found during
# the list scan. If not it will just
# skip printing the found IPs
unless up.empty?
puts "IPs FOUND: ".green
up.each do |ip|
puts ip
end
end
end
ls = list_scan
# checks to see if the list_scan is
# nil and if it is it will ru the ping_scan
if ls.nil?
puts "\n\n\n\n\nList Scan failed... None detected. Now performing Ping Scan\n\n\n".red
ping_scan
end
Banner Grabbing Multiple Sites
This scripts takes the URLS that are contained in an array and loops through all the elements of the array.
The script calls the “Snackhack2::BannerGrabber” class and gets the banner of the site using cURL which it prints the results in the terminal.
Banner grabbing can be used to try to guess what server is running a website. Which could allow an attacker to see if the web server version is vulnerable to a exploit.
bg = ["https://google.com",
"https://kinsta.com", "https://porchlightshop.com", "https://www.drrajatgupta.com"]
sn = Snackhack2::BannerGrabber.new
bg.each do |site|
sn.site = site
sn.curl
end
Checking Sites for WordPress
This script will check for WordPress users, perform a port scan on the site and grab the site’s metadata. For this gem to work, the colorize gem needs to be installed.
This gem can be installed by running the command: gem install colorize. Meta elements are tags used in HTML to document meta data about the site like social media URLS, keywords, authors and the description of the site.
# frozen_string_literal: true
require_relative '../lib/snackHack2'
require 'colorize'
#print('Enter URL (with HTTPS://): ')
#url = gets.chomp
url = "https://abc.com"
print("\n\n\n")
puts "[+] Checking for Drupal...\n".red
d = Snackhack2::Drupal.new
d.site = url
d.all
puts "\n--------\n"
puts "[+] Checking for WordPress...\n".red
wp = Snackhack2::WordPress.new
wp.site = url
wp.run
puts "\n--------\n"
puts "[+] Checking for TomCat...\n".red
tc = Snackhack2::TomCat.new
tc.site = url
tc.run
puts "\n--------\n"
puts "[+] Checking the site for Google Analytics...\n".red
ga = Snackhack2::GoogleAnalytics.new
ga.site = url
ga.run
puts "\n--------\n"
puts "[+] Grabbing the Banner...\n".red
bg = Snackhack2::BannerGrabber.new
bg.site = url
bg.run
puts "--------\n"
puts "[+] Checking Robots.txt...\n".red
r = Snackhack2::Robots.new(url)
r.run
puts "\n--------\n"
puts "[+] Getting HTML comments\n".red
c = Snackhack2::Comments.new
c.site = "https://abc.com"
c.run
puts "\n--------\n"
puts "[+] Getting Site's SSL Cert\n".red
ssl = Snackhack2::SSLCert.new
ssl.site = "https://google.com"
ssl.get_cert
puts "\n--------\n"
puts "[+] Getting links of a site\n".red
sl = Snackhack2::WebsiteLinks.new
sl.site = "https://abc.com"
sl.run
puts "\n--------\n"
puts "[+] Getting a website's META data\n".red
meta = Snackhack2::WebsiteMeta.new
meta.site = "https://abc.com"
meta.run
puts "\n--------\n"
puts "[+] Getting a website's META descriptio\n".red
meta.description
puts "\n--------\n"
puts "[+] Getting a website's site.xml\n".red
xml = Snackhack2::SiteMap.new
xml.site = "https://michaelmeade.org"
xml.run
puts "\n--------\n"
puts "[+] Getting a website's dns records\n".red
dns = Snackhack2::Dns.new
dns.site = "abc.com"
puts "A Record: "
dns.a.each do |a|
puts a
end
puts "\n\n\n"
puts "NamerServer: "
dns.nameserver.each do |ns|
puts ns
end
puts "\n\n\n"
puts "SOA: "
dns.soa.each do |s|
puts s
end
puts "\n\n\n"
puts "TXT: "
dns.txt.each do |txt|
puts txt
end
puts "\n\n\n"
puts "AAAAA: "
dns.aaaa.each do |a|
puts a
end
puts "\n\n\n"
puts "hinfo: "
dns.hinfo.each do |h|
puts h
end
puts "\n\n\n"
puts "mx: "
dns.mx.each do |mx|
puts mx
end
puts "\n--------\n"
puts "[+] Getting a website's Phone Numbers\n".red
d = Snackhack2::PhoneNumber.new
d.site = "https://www.hardin.kyschools.us/schools-1/school-phone-numbers"
d.run
#d.spider
puts "\n--------\n"
Scrapping the Top Million sites for Google Analytics
Uses a file that contains the top million sites on the web to extract the Google Analytics from those sites. The scripts can be found here.
require_relative '../lib/snackHack2'
ga = Snackhack2::GoogleAnalytics.new
File.readlines("top-1000000-domains.txt").each do |site|
site = site.strip
ga.site = "https://#{site}"
begin
g = ga.run.shift
rescue
end
unless g.eql?(nil)
unless g.include?("[+] No Google Analytics found :(")
p g
puts site
File.open("top_gas.txt", 'a') { |file| file.write("#{g}:#{site}\n") }
end
end
end
Getting Comments
The purpose of this script is to get extract Comments in Ruby programs. It will print out the comments found if any. The script will also extract HTML comments found in a website.
require '../lib/snackHack2'
rc = Snackhack2::RubyComments.new
rc.file = "test_comments.txt"
rc.comments
rc.comment_block
puts "[+] Getting HTML comments\n".red
c = Snackhack2::Comments.new
c.site = "https://abc.com"
c.run
Finding WordPress Plugins
This script will try to find if the site is using any of the many WordPress plugins.
require_relative '../lib/snackHack2'
wp = Snackhack2::BannerGrabber.new
ww = Snackhack2::WordPress.new
s = ["https://www.sccfd.org", "https://www.caicorp.com", "https://michaelmeade.org"]
s.each do |ss|
ww.site = ss
ww.find_plugins
puts ww.site
end